
Kernel Principal Component Analysis Allowing Sparse Representation and Sample Selection
Article Sidebar
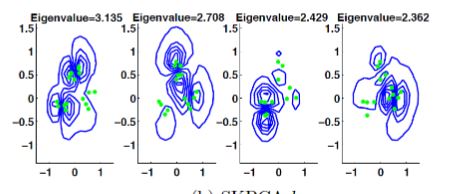
Main Article Content
Abstract
Kernel principal component analysis (KPCA) is a kernelized version of principal component analysis (PCA). A kernel principal component is a superposition of kernel functions. Due to the number of kernel functions equals the number of samples, each component is not a sparse representation. Our purpose is to sparsify coefficients expressing in linear combination of kernel functions, two types of sparse kernel principal component are proposed in this paper. The method for solving sparse problem comprises two steps: (a) we start with the Pythagorean theorem and derive an explicit regression expression of KPCA and (b) two types of regularization $l_1$-norm or $l_{2,1}$-norm are added into the regression expression in order to obtain two different sparsity form, respectively. As the proposed objective function is different from elastic net-based sparse PCA (SPCA), the SPCA method cannot be directly applied to the proposed cost function. We show that the sparse representations are obtained in its iterative optimization by conducting an alternating direction method of multipliers. Experiments on toy examples and real data confirm the performance and effectiveness of the proposed method.
Article Details
References
I. Jolliffe, Principal Component Analysis.Springer, 1986.
C. M. Bishop, Pattern Recognition and MachineLearning. Springer. 2006.
B. Scholkopf, A. Smola, and K. Muller, Non-linear component analysis as a kernel eigenvalue
problem," Neural Computation, vol. 10, no. 5 pp. 299{1319, July, 1998.
N. Aronszajn, Theory of reproducing kernels,"Transactions of the American Mathematical Society, vol. 68, no. 3, pp. 337{404, 1950.
A. J. Smola, O. L. Mangasarian, and B. Scholkopf, Sparse kernel feature analysis," In Classi_cation, Automation, and New Media, Springer, pp. 167{178, 2002.
A. Smola, and B. Scholkopf, (2000). Sparse greedy matrix approximation for machine learning," In Proceedings of the Seventeenth International Conference on Machine Learning, ICML'00, San Francisco, CA. Morgan Kaufmann, pp.911{918, 2000.
B. Scholkopf, S. Mika, C. Burges, P. Knirsch,K. Muller, G. Ratsch, and A. Smola, Input space versus feature space in kernel-based methods," Neural Networks, IEEE Transactions on,vol. 10, no. 5, pp. 1000{1017, Sep. 1999.
M. E. Tipping, Sparse kernel principal component analysis," In Advances in Neural Information Processing Systems 13, Cambridge, MA:MIT Press, pp. 633{639, 2001.
X. Jiang, Y. Motai, R. Snapp, and X. Zhu, Accelerated kernel feature analysis," In 2006 IEEE
Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), 17-22 June 2006, New York, NY, USA, pp. 109{116.
R. Vollgraf, and K. Obermayer, Sparse optimization for second order kernel methods," In
Neural Networks, 2006. IJCNN '06. International Joint Conference on, pp. 145{152, 2006.
Z. K. Gon, J. Feng, and C. Fyfe, A comparison of sparse kernel principal component analysis methods". In Knowledge-Based Intelligent Engineering Systems and Allied Technologies, 2000. Proceedings. Fourth International Conference on, vol. 1, pp. 309{312.
Y. Xu, D. Zhang, J. Yang, J. Zhong, and J. Yang,Evaluate dissimilarity of samples in feature
space for improving kpca," International Journal of Information Technology & Decision Making, vol. 10, no. 03, pp. 479{495, 2011.
Z. Hussain, and J. Shawe-Taylor, Theory of matching pursuit," In Advances in Neural In-
formation Processing Systems 21, D. Koller, D.Schuurmans, Y. Bengio, and L. Bottou, Eds.
Vancouver, BC, Canada: MIT Press, pp. 721{728, 2009.
M. E. Tipping, and C. M. Bishop, Probabilistic principal component analysis," Journal of the Royal Statistical Society, Series B, vol. 61, pp.611{622, 1999.
B. Scholkopf, and A. J. Smola, Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. MIT Press, Cambridge, MA, 2001.
Z. Hussain, J. Shawe-Taylor, D. Hardoon, and C. Dhanjal, Design and generalization analysis of orthogonal matching pursuit algorithms,"Information Theory, IEEE Transactions on, vol.57, no. 8, pp. 5326{5341, 2011.
J. A. K. Suykens, T. V. Gestel, J. Vandewalle,and B. D. Moor, A support vector machine for mulation to pca analysis and its kernel version," IEEE Transactions on Neural Networks, vol. 14, no. 2, pp. 447{450, 2003.
C. Alzate, and J. A. K. Suykens, Kernel component analysis using an epsilon-insensitive robust loss function," IEEE Transactions on Neural Networks, vol. 19, no. 9, pp. 1583{1598, 2008.
V. Vapnik Statistical Learning Theory NewYork: Wiley, 1998.
J. A. K. Suykens, and J. Vandewalle, Least squares support vector machine classi_ers," Neural Process. Lett., vol. 9, no. 3, pp. 293{300, 1999.
D. Wang, and T. Tanaka, Sparse kernel principal component analysis based on elastic net reg-
ularization," In 2016 International Joint Conference on Neural Networks (IJCNN), pp. 3703{3708, 2016.
L. Guo, P. Wu, J. Gao, and S. Lou, Sparse Kernel Principal Component Analysis via Sequential
Approach for Nonlinear Process Monitoring," InIEEE Access, vol. 7, pp. 47550{47563, 2019.
Y.Washizawa, Adaptive subset kernel principal component analysis for time-varying patterns,"Neural Networks and Learning Systems, IEEETransactions on, vol. 23, no. 12, pp. 1961{1973,2012.
T. Tanaka, Dictionary-based online kernel principal subspace analysis with double orthogonal-
ity preservation," In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE Interna-
tional Conference on, pp. 4045{4049, 2015.
H. Zou, and T. Hastie, Regularization and variable selection via the elastic net," Journal of the
Royal Statistical Society, Series B, vol. 67, pp.301{320, 2005.
H. Zou, T. Hastie, and R. Tibshirani, Sparse principal component analysis," Journal of Computational and Graphical Statistics, vol. 15, no.2, pp. 265{286, 2006.
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, J, Distributed optimization and statistical learning via the alternating direction method of multipliers," Foundations and Trends in Machine Learning., vol. 3, no. 1, pp. 1{122,Jan. 2011.
K. Sjostrand, L. Clemmensen, R. Larsen, and B. Ersb_ll, Spasm: A matlab toolbox for sparse statistical modeling," Journal of Statistical Software, pp. 1-24. 2012.
T. Tanaka, Y. Washizawa, and A. Kuh,Adaptive kernel principal components tracking," In Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conferenceon, pp. 1905{1908, 2012.
S. J. Wright, R. D. Nowak, and M. A. T.Figueiredo, Sparse reconstruction by separable approximation," Transactions on Signal Processing, vol. 57, no. 7, pp. 2479{2493, 2009.
P. Honeine, Online kernel principal componentanalysis: A reduced-order model," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, no. 9, pp. 1814{1826, 2012.
M. Lichman, UCI machine learning repository.